
- Pristatome „Instantaneous PowerLoss Storm“ – naują „Meta“ infrastruktūros testavimo paradigmą, skirtą valdyti ir sušvelninti momentinį arba nepastebimą energijos praradimą mūsų duomenų centruose.
- Dalinamės: kaip sukūrėme pasirengimą toleruoti akimirksnius esamų sistemų gedimus taikydami gilios gynybos strategijas; kompromisai, padaryti jį įgyvendinant, ir kaip mes patvirtinome savo pasirengimą.
Pasirengimas nelaimėms nėra neprivalomas. Uraganai, laukiniai gaisrai, energijos tiekimo ir tinklo sutrikimai bei daugybė kitų nelaimių scenarijų kelia pavojų mūsų duomenų centro (DC) infrastruktūrai.
Ankstyvojo įspėjimo sistemos ir išbandytos mažinimo strategijos jau puikiai pasitarnauja situacijose, kai turime kelias valandas ar daugiau pažangaus įspėjimo. Nors šios strategijos laikui bėgant subrendo, kai plečiame nuolatinės srovės buvimą, vis didėjantis mūsų infrastruktūros dydis ir įvairovė pareikalavo didesnio pasirengimo lygio nelaimėms, apie kurias nieko neįspėjame (tokioms, kurios įvyksta be jokio įspėjimo), pvz. momentinis galios praradimassu minimalus poveikis bendram parko prieinamumui.
„Momentaneous PowerLoss Storm“ yra nauja „Meta“ seniai sukurtos testavimo paradigma. Pasirengimas nelaimėms (DR) “Audra“ programa, kuri sudaro paskutinę gynybos liniją ir didžiausią saugos tinklą, kad būtų galima valdyti ir sumažinti momentinį arba nepastebimą galios praradimą dėl žinomos, atsirandančios ir nežinomos rizikos.
Kaip mes sukūrėme pasirengimą toleruoti momentinius esamų sistemų gedimus taikydami išsamias gynybos strategijas.
Galimybė susidoroti su momentiniu energijos praradimu turėjo būti sukurta nuo pat pradžių iki mūsų nuolatinės srovės krūvos, nuo mechaninių ir elektrinių įrenginių iki serverių stelažų, nuo saugyklos iki skaičiavimo ir branduolio. Špagatas konteinerių orkestrantas. Laimei, kiekviena iš šių architektūrų jau buvo sukurta su galios praradimo tolerancija kaip neatsiejamu komponentu.
Suteikia galimybę išsaugoti atmintyje esančius duomenis, kai stelažai nutrūksta naudojant baterijas ir Galios praradimo sirena (PLS) yra viena iš tokių galimybių. Kitas dalykas yra turėti tvirtą DC regiono asinchroninį signalizacijos mechanizmą „Twine“ paslaugoms nepasiekiamumo įvykių (UE) pavidalu. (Nuolatinės nuolatinės srovės regionas – toliau vadinamas „regionu“ – yra tas, kuriame keli nuolatinės srovės pastatai yra vienoje vietoje ir turi bendrą tinklo ir maitinimo ryšį).
Nors šie gebėjimai buvo išbandyti ir sustiprinti atskirų gedimų srityse atskiruose DC, mes nustatėme išskirtinius pažeidžiamumus scenarijuose, apimančiuose visą regioną. Be to, išbandydami regioną turėjome susidurti su ne tik masto (tipiškas regionas paprastai yra 50–60 kartų didesnis už tipiškų gedimų domenus) ir kopijų išdėstymo, bet ir su autonominio įkrovos problemomis.
Bootstrapping reiškia išjungto regiono paleidimą ir reikalavimą, kad milijonai paslaugų pradėtų veikti vienu metu ir savarankiškai atrastų viena kitą. Žemiau aprašome dvi problemas, su kuriomis susidūrėme įkrovimo metu, dėl kurių reikėjo priimti a diržo ir petnešų metodas kad apimtų visus galimus įvykius ir nenumatytus atvejus.
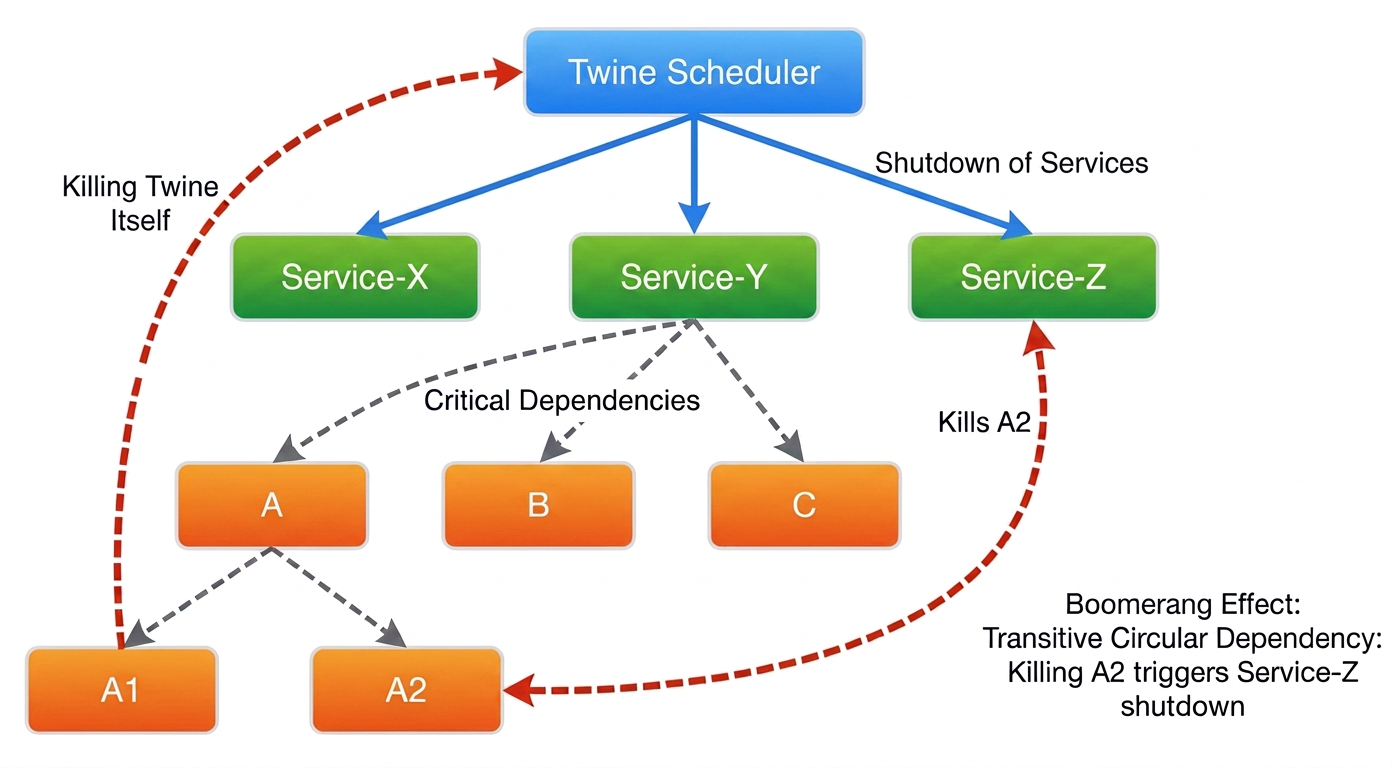
Reikšmingas dalykas, kuris mus persekiojo nuo pirmųjų dienų, yra priklausomybės, ypač baisūs. žiedinė priklausomybė, “mūsųoboros“, rizika! Mūsų „Twine“ orkestrantas turi valdymo plokštumos paslaugų rinkinį – Tvarkaraštisskirstytuvas, Brokeris, Uolus (koordinatorius) ir pan. – be kurių negalime teikti ar pradėti teikti kitų paslaugų regione. Nors cirkuliarinių priklausomybių rizika atliekant įprastas operacijas yra maža, rizika ir poveikis yra daug didesnis, kai paleidžiamas visas regionas. Tai tikra vištienos ir kiaušinio problema.
Tai išsprendėme identifikuodami kritinės paleidimo priklausomybės tarp valdymo plokštumos paslaugų, ir mes nuolat jas aptinkame anksti ir dažnai su Belljaro testai mūsų CI / CD vamzdynuose. Tai padėjo atskleisti ir pašalinti daugumą, jei ne visas, priklausomybės rizikas prieš jas panaudojant gamyboje. Atsižvelgdami į sparčią mūsų infrastruktūros raidą ir kaip diržo ir petnešų sprendimą, mums taip pat reikėjo pajėgumas į nutraukti bet kokias žiedines priklausomybes kuris galėjo atsitikti netikėtai. Tiksliai sukurtas Twine atkūrimo rinkinys suteikia šią „sparčiojo starto“ galimybę atkurti tas Twine paslaugas, kurios maitina pačią Twine. Kartu su Belljar ir Twrko mums pavyko sėkmingai nuraminti žiedinių priklausomybių šmėklą.
Taip pat susidūrėme su „bumerangas“ problema toje pačioje vietoje – kritinio signalo generatorius, veikiamas to paties signalo. UE, naudojamos paslaugų išjungimui ir atkūrimui organizuoti, baigė išjungti pačias orkestro valdymo plokštumos paslaugas, todėl paslaugos tapo našlaičiais, kurių negalėjo būtipjaunama“ (nes jie niekada negavo UE). Nors šią problemą buvo galima išspręsti sudėtingais sprendimais, pvz., iš anksto nustatyto paslaugų rinkinio neįtraukimas iš UE siuntimo sąrašo, nusprendėme taikyti paprastesnį ir tvaresnį metodą, leisdami valdymo plokštumos paslaugoms tiesiog „ignoruoti“ išjungimo signalus, susijusius su su energija susijusiomis UE.
Kompromisai, kurių buvo imtasi nustatant tinkamą patikimumo ir augimo greičio pusiausvyrą.
Nors įmanoma sukurti vandeniui atsparų atsparumą momentiniam praradimui, tai gali kainuoti infrastruktūros srityje arba rizikuoti pertvarkyti mūsų sistemas. Pastarasis netgi gali sukelti klaidingų teigiamų rezultatų, turinčių įtakos įprastoms operacijoms, riziką. Taigi, norėdami rasti tinkamą patikimumo ir inžinerijos pusiausvyrą, turėjome padaryti tam tikrus kompromisus.
Pradėjome nubrėždami ribą, kurios reikia vengti. Duomenų praradimas saugyklų ir duomenų bazių sistemoms, nuolatinė nuolatinės srovės įrenginių (mechaninė / elektrinė) žala arba ilgalaikis poveikis už vieno regiono ribų yra keletas dalykų, kuriuos aiškiai pažymėjome kaip stalo statymo reikalavimus. Laikinos aptarnavimo klaidos, stovo gedimai (neviršijant iš anksto nustatytos ribos) ir ribotas pasenimas paslaugų maršruto parinkimo lentelėse arba regiono nepasiekiamumo aptikimo metu (tai yra sudėtinga asinchroninių sistemų problema) buvo laikomos toleruotina rizika. Apskritai, tik problemos, kurių negalima sušvelninti taikant taisymą po incidento ir per pagrįstą vidutinį atsakymo laiką (MTTR), nepatenka į toleruotino poveikio ribą.
Kaip mes patvirtinome savo pasirengimą naudodamiesi momentine galios praradimo audra ir kaip tai leidžia mums stumti voką toliau.
Aukščiau nurodytų lūkesčių patvirtinimas ir pasiruošimas, išjungus energiją iš didelio gamybos regiono, sukėlė didelę riziką su keliais žinomais ir nežinomais nežinomaisiais. Kad išspręstume šią vištienos ir kiaušinių problemą, kai reikia rizikuoti, kad būtų išvengta rizikos, nustatėme laipsnišką metodą, pagal kurį patvirtinome savarankiškas problemas, tokias kaip priklausomybės, kai sukuriami nauji / ikigamybiniai regionai, taip pat atlikome bandymus šešėliniuose regionuose, kurie atkartoja gamybos regionus. Vėliau galėjome sėkmingai išbandyti savo naujausiuose (taigi ir mažiausiuose) gamybos regionuose su ribotu sprogimo spinduliu. Galiausiai išjungėme didelius gamybos regionus, kuriuose yra svarbios saugyklos, AI ir duomenų saugyklos darbo krūviai. Šiame etape mes pavadinome šias Audros pratimus Momentinės „PowerLoss“ audros.
Nuo 10 000 pėdų aukščio audrą sudaro maitinimo šaltinio gedimas, kuris nedelsiant išjungiamas visame regione, o po trumpo MTTR taisomojo „nuleidimo“ imamasi veiksmų, kad paveiktas regionas būtų atskirtas nuo pasaulinių valdiklių / planuotojų. Taip pat siekėme vengti bet kokių prevencinių veiksmų prieš bandymą, kad iš tikrųjų būtų netikėtas galios praradimas. Testui pasirinktas MTTR atspindėjo tipišką MTTR, matomą realių incidentų scenarijuose.
Kiekvienas iš šių pratimų padėjo nuolat apmokyti mūsų infrastruktūrą ir inžinierius siekiant ilgalaikio tikslo – valdyti regiono praradimą taip pat sklandžiai, kaip ir subregioninio gedimo srities praradimą.
Žingsniai į ateitį: lėtas yra sklandus. Sklandus yra greitas
Net ir laikantis visų atsargumo priemonių, tai nebuvo visiškai sklandus kelias, o kelias mokytis ir tobulėti, o tai ne tik pagerino mūsų testavimo galimybes, bet ir persmelkė visą mūsų infrastruktūrą su keliais esamų sistemų architektūriniais patobulinimais.
Kartu mūsų infra buvo sparčiai tobulinamas, kad atitiktų daugybę pajėgumų ir AI naudojimo atvejų. Greitai judėti įmanoma tik tada, kai turime tvirtus pagrindus. Patikimumas ir greitis yra du tos pačios monetos briaunos. Negalite turėti vieno be kito. Galimybė atkurti regioną po momentinio gedimo padėjo tvirtą pagrindą, kuris padėjo mums diegti nuolatinės srovės projektų naujoves ir juos patvirtinti, didinti patikimumą sparčiai diegiant pajėgumus ir toliau didinti riziką, kurią galime toleruoti.
Nors ankstesnė „Storms“ dažniausiai patvirtino saugyklos ir duomenų bazių pagrindines programas, mes naudojame tą pačią laipsnišką strategiją, kad patikrintume regionus, kuriuose yra tiesioginis klientų srautas, kad būtų išvengta momentinių gedimų. (Daugiau apie tai būsimame įraše!) Mes taip pat nuolat peržiūrime ir peržiūrime kompromisus, atsižvelgdami į naujus iššūkius, kylančius šiame augimo etape.


