
Neseniai atliktame LG AI tyrimų dokumente teigiama, kad tariamai „atvirų“ duomenų rinkiniai, naudojami mokant AI modeliams, gali pasiūlyti klaidingą saugumo jausmą – sužinoti, kad beveik keturi iš penkių AI duomenų rinkinių, pažymėtų kaip „komerciškai tinkami“, iš tikrųjų turi paslėptą teisinę riziką.
Tokia rizika svyruoja nuo neatskleistos autorių teisių saugomos medžiagos įtraukimo iki ribojančių licencijavimo terminų, palaidotų giliai duomenų rinkinio priklausomybėje. Jei dokumento išvados yra tikslios, įmonėms, kurios remiasi viešaisiais duomenų rinkiniais, gali tekti persvarstyti savo dabartinius AI vamzdynus arba rizikuoti teisine pozicija pasroviui.
Tyrėjai siūlo radikalų ir potencialiai prieštaringai vertinamą sprendimą: AI pagrįsti atitikties agentai, galintys greičiau ir tiksliau nei žmonių teisininkai nuskaityti ir tikrinti duomenų rinkinių istoriją.
Straipsnyje teigiama:
„Šis dokumentas pasisako už tai, kad teisinė AI mokymo duomenų rinkinių rizika negali būti nustatyta vien tik peržiūrint paviršiaus lygio licencijos sąlygas; Norint užtikrinti atitiktį, būtina išsami duomenų rinkinio perskirstymo analizė.
„Kadangi tokia analizė viršija žmogaus galimybes dėl jo sudėtingumo ir masto, AI agentai gali užpildyti šią spragą, atlikdami ją didesniu greičiu ir tikslumu. Be automatizavimo kritinė teisinė rizika išlieka iš esmės neištyrinėta, kyla pavojus etiškam AI plėtrai ir reguliavimo laikymusi.
„Mes raginame AI tyrimų bendruomenę pripažinti teisinę analizę kaip pagrindinį reikalavimą ir laikytis AI pagrįstų požiūrių kaip perspektyvaus kelio į keičiamo duomenų rinkinio laikymąsi.“
Išnagrinėję 2 852 populiarius duomenų rinkinius, kurie pasirodė komerciškai tinkami pagal jų individualias licencijas, tyrėjų automatizuota sistema nustatė, kad tik 605 (apie 21%) iš tikrųjų buvo teisiškai saugūs komercializavimui, kai tik buvo atsektos jų komponentai ir priklausomybės.
Naujasis popierius pavadintas Nepasitikėkite matomomis licencijomis-duomenų rinkinio atitiktis reikalauja masinio masto AI varomo gyvenimo ciklo sekimoir gaunamas iš aštuonių LG AI tyrimų tyrėjų.
Teisės ir neteisybės
Autoriai pabrėžia iššūkius, su kuriais susiduria įmonės, besitęsiančios į priekį plėtojant AI, vis labiau neaiškioje teisinėje aplinkoje – nes buvusi akademinio „sąžiningo naudojimo“ mąstysena aplink duomenų rinkinių mokymus suteikia galimybę lūžusią aplinką, kurioje teisinė apsauga neaiški, o saugus uostas nebėra garantuojamas.
Kaip neseniai pažymėjo vienas leidinys, įmonės vis labiau gina savo mokymo duomenų šaltinius. Autorius Adomas Buickas komentarai*:
„(O„ Openai “atskleidė pagrindinius GPT-3 duomenų šaltinius, dokumente, kuriame pristatoma GPT-4 atskleista Tik tai, kad duomenys, kuriais buvo išmokytas modelis, buvo „viešai prieinamų duomenų (pvz., Interneto duomenys) ir duomenų, licencijuotų iš trečiųjų šalių tiekėjų, mišinys.
„AI kūrėjai, kurie daugeliu atvejų nepateikė jokio paaiškinimo.
„Savo ruožtu„ Openai “pateisino savo sprendimą neišleisti papildomos informacijos apie GPT-4 remdamasis susirūpinimu dėl„ konkurencinės kraštovaizdžio ir didelio masto modelių saugos padarinių “, o ataskaitoje dar daugiau paaiškinimų“.
Skaidrumas gali būti nemandagus terminas – arba tiesiog klaidingas; Pavyzdžiui, „Adobe“ pavyzdinis „Firefly Generative“ modelis, mokė atsargų duomenis, kad „Adobe“ turėjo teisę išnaudoti, tariamai siūlo klientams patikinimus apie jų naudojimo sistemos teisėtumą. Vėliau pasirodė keletas įrodymų, kad „Firefly Data Pot“ tapo „praturtinta“ potencialiai autorių teisių saugomais duomenimis iš kitų platformų.
Kaip mes aptarėme anksčiau šią savaitę, auga iniciatyvos, skirtos užtikrinti licencijų laikymąsi duomenų rinkiniuose, įskaitant tokią, kuri tik surinks „YouTube“ vaizdo įrašus su lanksčiomis „Creative Commons“ licencijomis.
Problema ta, kad licencijos savaime gali būti klaidingos arba suteiktos klaidomis, kaip atrodo naujasis tyrimas.
Tiriant atvirojo kodo duomenų rinkinius
Sunku sukurti tokią vertinimo sistemą kaip autorių ryšys, kai kontekstas nuolat keičiasi. Todėl dokumente teigiama, kad „Nexus“ duomenų atitikties sistemos sistema yra pagrįsta „įvairiais precedentais ir teisiniais pagrindais šiuo metu“.
„Nexus“ naudoja AI varomą agentą, vadinamą Automatinis atitiktis Automatizuotoms duomenų atitikimui. Automatinį laikymąsi sudaro trys pagrindiniai moduliai: naršymo modulis žiniatinklio tyrinėjimui; Informacijos ištraukimo modulis, pateikiantis klausimus, pateikiami (QA); ir teisinės rizikos įvertinimo balų modulis.
Automobiliai prasideda nuo vartotojo pateikto tinklalapio. AI ištraukia pagrindinę informaciją, ieško susijusių išteklių, nustato licencijos sąlygas ir priklausomybes ir priskiria teisinio rizikos balą. Šaltinis: https://arxiv.org/pdf/2503.02784
Šie moduliai yra maitinami tiksliai suderintais AI modeliais, įskaitant EXAONE-33.5-32B instruktoriaus modelį, išmokytą sintetinių ir žmogaus pažymėtų duomenų. Automatiškai laikomasi duomenų bazės, skirtos talpyklos kaupimo rezultatams, kad padidintų efektyvumą.
Automobilių laikymasis prasideda nuo vartotojo pateikto duomenų rinkinio URL ir traktuoja jį kaip pagrindinį subjektą, ieškant savo licencijos terminų ir priklausomybių bei rekursyviai sekant susietų duomenų rinkinius, kad būtų sukurta priklausomybės nuo licencijos diagrama. Kai visos jungtys bus pažymėti, jis apskaičiuoja atitikties balus ir priskiria rizikos klasifikacijas.
Naujajame darbe išdėstyta duomenų atitikties sistema nustato įvairius† Duomenų gyvavimo cikle dalyvaujančių subjektų tipai, įskaitant duomenų rinkiniaikuris sudaro pagrindinį AI mokymo įvestį; Duomenų apdorojimo programinė įranga ir AI modeliaikurie naudojami duomenims transformuoti ir panaudoti; ir Platformos paslaugų teikėjaitai palengvina duomenų tvarkymą.
Sistema holistiškai vertina teisinę riziką, atsižvelgdama į šiuos įvairius subjektus ir jų tarpusavio priklausomybes, peržengdama „Rote“ duomenų rinkinių licencijų vertinimą, įtraukiant platesnę komponentų ekosistemą, susijusią su AI plėtroje.
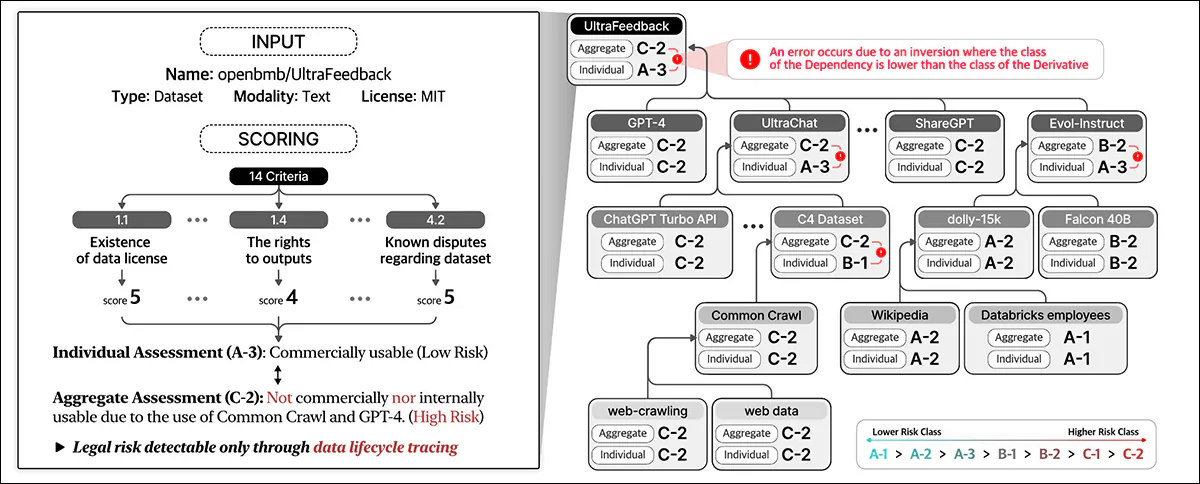
Duomenų laikymasis įvertina teisinę riziką per visą duomenų gyvavimo ciklą. Jis priskiria balus, pagrįstus duomenų rinkinio informacija ir 14 kriterijų, klasifikuojant atskirus subjektus ir kaupiančią riziką priklausomybės.
Mokymai ir metrika
Autoriai ištraukė 1 000 populiariausių duomenų rinkinių URL, esant „Hugning Face“, atsitiktinai paaukštindami 216 elementus, kad sudarytų bandymų rinkinį.
„Exaone“ modelis buvo tiksliai suderintas su autorių pasirinktiniu duomenų rinkiniu, naudojant navigacijos modulį ir klausimų siunčiamą modulį, naudojant sintetinius duomenis, ir balų skaičiavimo modulį, naudojant žmogaus pažymėtus duomenis.
Žemės tiesos etiketes sukūrė penki teisės ekspertai, mokomi mažiausiai 31 valandą atliekant panašias užduotis. Šie žmonių ekspertai rankiniu būdu nustatė 216 bandymo atvejų priklausomybes ir licencijų sąlygas, tada diskusijomis surinko ir patikslino savo išvadas.
Naudojant apmokytą, žmogaus kalibruotą automatinio atitikimo sistemą, patikrintą pagal „CHATGPT-4O“ ir „Pasiplhety Pro“, licencijos sąlygose buvo rasta daugiau priklausomybių:
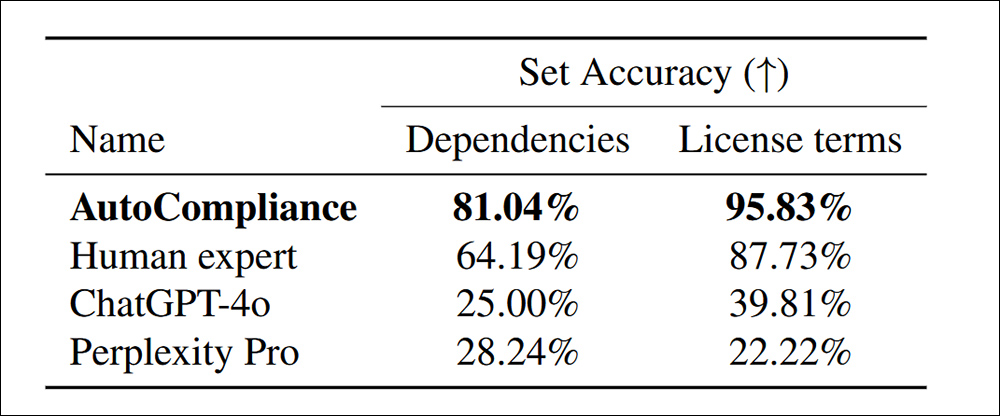
Tikslumas nustatant priklausomybes ir licencijų sąlygas 216 vertinimo duomenų rinkiniams.
Straipsnyje teigiama:
„Automobilių laikymasis žymiai pralenkia visus kitus agentus ir žmonių ekspertus, kiekvienoje užduotyje pasiekdamas 81,04% ir 95,83% tikslumą. Priešingai, tiek „ChatGPT-4o“, tiek „AffiSity Pro“ rodo atitinkamai mažą šaltinio ir licencijos užduočių tikslumą.
„Šie rezultatai pabrėžia aukštesnį automatinio laikymosi rezultatą, parodant jo veiksmingumą atliekant abi užduotis, tiksliai tiksliai tvarkant užduotis, kartu parodant didelę veiklos atotrūkį tarp AI pagrįstų modelių ir šių sričių žmogaus ekspertų.“
Kalbant apie efektyvumą, automatinio apskyrimo metodas truko tik 53,1 sekundės, priešingai nei 2418 sekundžių, kad būtų lygiavertis žmogaus įvertinimas tose pačiose užduotyse.
Be to, vertinimo vykdymas kainavo 0,29 USD, palyginti su 207 USD žmonių ekspertams. Vis dėlto reikia pažymėti, kad tai grindžiama GCP A2-MEGAGPU-16GPU mazgo nuomojimu per mėnesį, kurio kaina yra 14 225 USD per mėnesį-tai reiškia, kad toks ekonominis efektyvumas yra susijęs pirmiausia su didelio masto operacija.
Duomenų rinkinio tyrimas
Analizei tyrėjai pasirinko 3 612 duomenų rinkinius, sujungusius 3000 labiausiai atsisiųstų duomenų rinkinių iš apkabinimo veido su 612 duomenų rinkiniais iš 2023 m. Duomenų kilmės iniciatyvos.
Straipsnyje teigiama:
„Pradėję nuo 3 612 tikslinių subjektų, iš viso nustatėme 17 429 unikalius subjektus, kuriuose 13 817 subjektai pasirodė kaip tikslinių subjektų tiesioginės ar netiesioginės priklausomybės.
„Atlikdami empirinę analizę, mes manome, kad subjektas ir jo priklausomybės nuo licencijos diagrama turi vienkartinę struktūrą, jei subjektas neturi priklausomybių ir daugiasluoksnę struktūrą, jei ji turi vieną ar daugiau priklausomybių.
„Iš 3 612 tikslinių duomenų rinkinių 2 086 (57,8%) turėjo daugiasluoksnes struktūras, tuo tarpu kitos 1 526 (42,2%) turėjo vienkartines struktūras, neturinčias priklausomybių.“
Autorių teisių saugomus duomenų rinkinius galima perskirstyti tik naudojant teisinę valdžią, kuri gali būti susijusi su licencija, autorių teisių įstatymo išimtimis ar sutarties sąlygomis. Neteisėtas perskirstymas gali sukelti teisinių padarinių, įskaitant autorių teisių pažeidimus ar sutarčių pažeidimus. Todėl būtina aiškiai nustatyti neatitikimą.
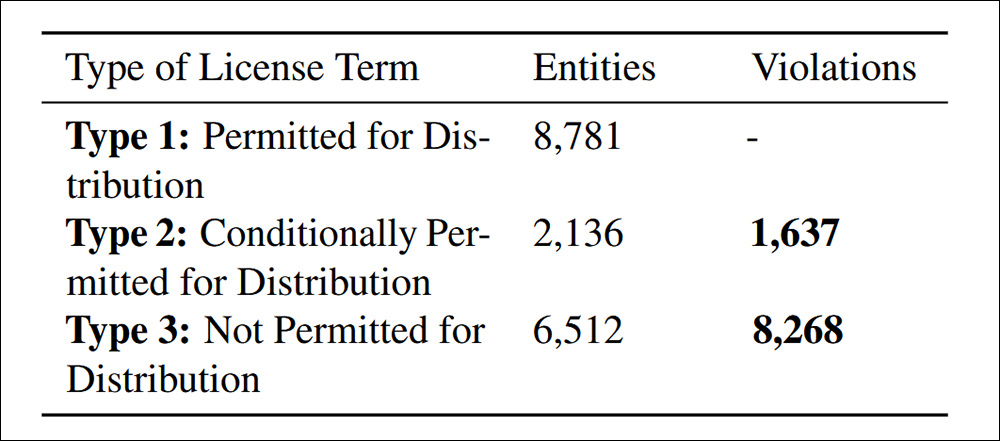
Paskirstymo pažeidimai, rasti pagal cituojamą straipsnio kriterijų 4.4. duomenų atitikties.
Tyrime nustatyta, kad 9 905 neatitinkančių duomenų rinkinio perskirstymo atvejai, padalyti į dvi kategorijas: 83,5% buvo aiškiai draudžiami pagal licencijavimo sąlygas, todėl perskirstymas buvo aiškus teisinis pažeidimas; ir 16,5% duomenų rinkiniai buvo su prieštaringomis licencijų sąlygomis, kai teoriškai buvo leidžiamas perskirstymas, tačiau kurie neatitiko reikiamų sąlygų, sukuriant pasroviui teisinę riziką.
Autoriai pripažįsta, kad „Nexus“ siūlomi rizikos kriterijai nėra universalūs ir gali skirtis priklausomai nuo jurisdikcijos ir AI taikymo, ir kad ateityje patobulinimai turėtų būti sutelkti į prisitaikymą prie besikeičiančių globalių taisyklių, tobulinant AI pagrįstą teisinę apžvalgą.
Išvada
Tai yra platus ir daugiausia nedraugiškas popierius, tačiau skirtas bene didžiausias atsilikęs veiksnys dabartiniame AI pramonėje – galimybe, kad, matyt, „atvirus“ duomenis vėliau pareikalaus įvairūs subjektai, asmenys ir organizacijos.
Pagal DMCA pažeidimai gali legaliai skirti didžiules baudas už a per atvejį pagrindas. Ten, kur pažeidimai gali patekti į milijonus, kaip tyrėjų aptiktais atvejais, potenciali teisinė atsakomybė yra tikrai reikšminga.
Be to, įmonės, kurioms gali būti įrodyta, kad naudos iš aukštesnio lygio duomenų, negali (kaip įprasta) teigti, kad nežinojimas yra pasiteisinimas, bent jau įtakingoje JAV rinkoje. Šiuo metu jie neturi jokių realių įrankių, su kuriais būtų galima įsiskverbti į labirintų padarinius, palaidotus tariamai atvirojo kodo duomenų rinkinio licencijų sutartyse.
Problema formuojant tokią sistemą kaip „Nexus“ yra ta, kad ji būtų pakankamai sudėtinga, kad ji būtų kalibruota vienoje vietoje JAV viduje, arba vienos tautos pagrindu ES viduje; Perspektyva sukurti tikrai globalią sistemą (tam tikrą „Interpol“ duomenų rinkinio kilmę) kenkia ne tik prieštaringi įvairių susijusių vyriausybių motyvai, bet ir tai, kad šioje srityje tiek šios vyriausybės, tiek jų dabartiniai įstatymai šiuo atžvilgiu nuolat keičiasi.
* Mano hipersaitų pakeitimas autorių citatomis.
† Straipsnyje nurodomi šeši tipai, tačiau paskutiniai du nėra apibrėžti.
Pirmą kartą paskelbtas 2025 m. Kovo 7 d., Penktadienį


